Their methods for computing population are explained. I can't find any licensing or usage restrictions on the data, so I'll have to clear that up before doing anything serious with it. Let's download something and read it in.
The download form asks for a few details, but there's no email check (or 'I have read your terms and conditions' checkbox) so fill in as honestly as your conscience requires. You'll get a zip file to download.
When unzipped you'll have three files. For Benin these are called apben10v3 with extensions hdr, flt and prj.
The flt file is the data, the hdr is header info, and prj is projection info. Use gdalinfo to get a summary - run it on the flt file:
$ gdalinfo apben10v3.flt
Driver: EHdr/ESRI .hdr Labelled
Files: apben10v3.flt
apben10v3.hdr
apben10v3.prj
[WGS84 coordinate system info here]
Origin = (0.773989957311480,12.409206711176100)
Pixel Size = (0.000833300000000,-0.000833300000000)
Corner Coordinates:
Upper Left (0.7739900,12.4092067) (0d46'26.36"E,12d24'33.14"N)
Lower Left (0.7739900,6.2252874) (0d46'26.36"E,6d13'31.03"N)
Upper Right (3.8522002,12.4092067)(3d51' 7.92"E,12d24'33.14"N)
Lower Right (3.8522002,6.2252874) (3d51' 7.92"E,6d13'31.03"N)
Center (2.3130951,9.3172471) (2d18'47.14"E, 9d19' 2.09"N)
Band 1 Block=3694x1 Type=Byte, ColorInterp=Undefined
NoData Value=-9999
All pretty good. A standard ESRI file (except there's often nothing really standard about ESRI file formats). Let's read it and plot it using the raster package:
> bpop=raster("./apben10v3.flt")
> image(bpop)

Oh dear. Reading the docs about these files tells me that sometimes gdal just doesn't get it right. It said "Type=Byte", but the file is 109652696 bytes long, which is exactly 7421x3694x4 bytes. These are 4 byte values. In fact the AfriPop page says these files are "ESRI Float". Luckily there's an easy way to persuade gdal these are floats. Open up the hdr file (NOT the flt file. Don't open the flt file!) in a text editor (emacs, vi, notepad++, notepad) and add:
pixeltype float
to the items. Then try again:
> bpop=raster("./apben10v3.flt")
> plot(bpop,asp=1)

Looks good. Note we can get away with asp=1 since we're close to the equator. Or we can give it a projection:
projection(bpop)="+proj=tmerc"
plot(bpop)
and that's just as good. We can also zoom in using the very nifty zoom function from the raster package:


Note that the raster package does a really good job of dealing with large rasters. When plotting these things it is sampling the raster file so not all of it is read into memory. I don't have a monitor capable of showing 7000x3000 pixels (yet) so raster just grabs enough to look good. But if you try and do anything with this size of raster, you will strangle your machine and it may die. Don't do this:
plot(log(bpop))
for example. Let's sample our raster down a bit for some more exploring. First I need to restart R after the last line crashed out. I'll sample down to something of the order of a few hundred pixels by a few hundred pixels by specifying the size as 500*500 - sampleRegular will work out the exact resolution, keeping the aspect ratio. It's smart like that:
> library(raster)
> bpop=raster("apben10v3.flt")
> projection(bpop)="+proj=tmerc"
> plot(bpop)
> bpop2 = sampleRegular(bpop, 500*500, asRaster=TRUE)
> bpop2
class : RasterLayer
dimensions : 708, 352, 249216 (nrow, ncol, ncell)
resolution : 0.008744915, 0.008734349 (x, y)
extent : 0.77399, 3.8522, 6.225287, 12.40921 (xmin, xmax, ymin, ymax)
coord. ref. : +proj=tmerc +ellps=WGS84
values : in memory
min value : 0
max value : 336.4539
> plot(bpop2)
> plot(log(bpop2))
[Perhaps we should use 'resample' here?] Now the log plot is doable:

BUT these values are now wrong. The units of the original data are persons per grid square. Our grid squares are now bigger then the original grid squares, so more people live in them. We can correct this by scaling by the ratio of the cell sizes:
> bpop2= bpop2 * prod(res(bpop2))/prod(res(bpop))
> plot(log(bpop2))
and now we get a more correct map:
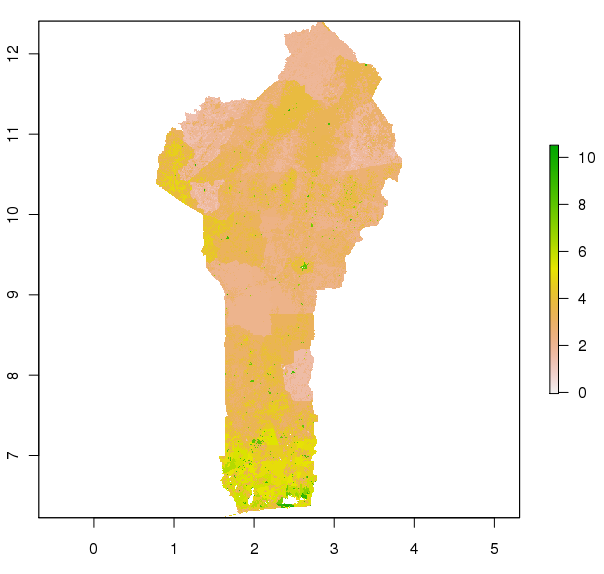
I'm not sure how 'correct' or optimal this is of downsampling population density grids is - for example the total population (sum of grid cells) will be slightly different. Perhaps it is better to rescale the sampled grid to keep the total population the same? Thoughts and musings in comments for discussion please!





